Running Open Source LLMs on Your Local Machine — The Easy Way
Without a doubt, large language models (LLMs) are among the most useful tools developed in recent years. The advantages and utilities of these AI-driven models have profoundly changed our lives. Typically, we access these models through web apps like ChatGPT or Gemini, which offer easy-to-use interfaces. However, there’s another way to interact with LLMs without relying on the servers of these companies or compromising your privacy. In this post, we’ll discuss the advantages of running LLMs on your local machine, explain how to do it, and answer some common questions.
Advantages and Disadvantages of Running LLMs on Your Local Machine
Advantages
Running LLMs on your local machine has several benefits:
- Unlimited Usage: You are not restricted by token limits or subscription fees, which is advantageous if you use the model frequently.
- Privacy: Your personal data remains on your machine, eliminating concerns about data exposure on external servers.
- Customization: You can use uncensored models, which can be beneficial for avoiding biases, conducting research, or simply adhering to your own principles of open-source usage.
Disadvantages
However, there are some downsides:
- Hardware Requirements: Larger models require significant storage and RAM. For example, a model like Mixtral may need up to 80GB of storage just to host it.
- Performance: Better models demand more computational power, which might not be feasible for all users.
How to Run LLMs on Your Machine
Running LLMs locally is straightforward and doesn’t require advanced knowledge. Here’s a step-by-step guide:
- Install Ollama: Visit the official site Ollama and download the installer for your system. Despite the “preview” label on the Windows installer, it is fully functional and well-tested.
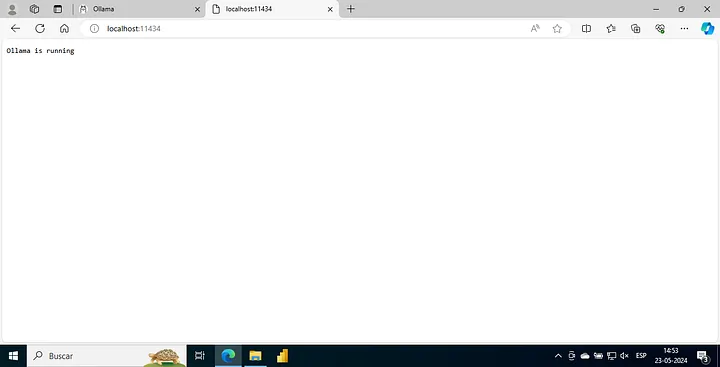
- Setup Ollama: Once installed, Ollama acts as a local server for running models. If everything is set up correctly, it will be running on port 11434 of your localhost.
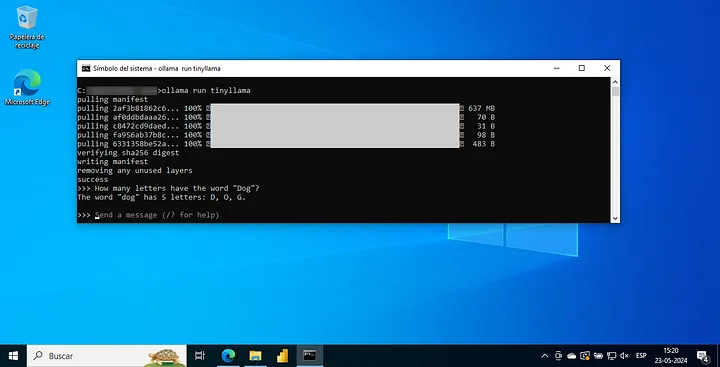
- Install and Run a Model: Select a model from the Ollama website. Models are typically categorized by size: small models (7 billion parameters), medium models (15 billion parameters), and large models (26 to 70 billion parameters). Copy the command for the desired model and run it in your command line interface (CLI). The model will be downloaded and ready to use.
Frequently Asked Questions
Can I Only Use the CLI?
While the CLI is a primary method, developers with experience can create their own applications using the endpoints provided by Ollama. You’ll need an HTTP client and a JSON parser. More details on the REST API usage can be found in the Ollama repository.
Are These Models Uncensored?
Some models are uncensored, like Llama2-uncensored or WizardLM-uncensored. You can use these models as shown in the examples. While it’s technically possible to uncensor any model, retraining a model is a complex and time-consuming task¹.
Can These Models Create Images Like Midjourney or DALL-E?
Not really. The most advanced models can analyze images but cannot create them.
Can These Models Be Used in Other Languages Like Spanish or Chinese?
Most models primarily “speak” English. However, some models, like Mixtral, support other languages such as German, Spanish, and Italian.
I hope you found this post helpful and that it provides a solid foundation for implementing these marvelous tools, the LLMs, on your own machine.
- If you’re interested in how to uncensor a model, you can check out this guide https://erichartford.com/uncensored-models.